
A modern, modular platform for compiling International Merchandise Trade Statistics (IMTS), or any other official statistics, built by United Nations Statistics Division in collaboration with Eurostat. This page summarizes capabilities, modules, and development activities.
(Jan 2026)
What is TDT?
TDT (Trade Data Tools) is a next generation, open-source, web based platform that transforms raw administrative trade data into validated, official statistics through automated pipelines and collaborative workflows. By replacing fragmented, manual processes and legacy tools, TDT enables faster, higher quality IMTS at lower cost, strengthens national capacity, and supports the timely release of data for evidence based policy. Furthermore, TDT simplifies data submission to the global databases, such as UN Comtrade, thereby improving timeliness and user relevance. It upgrades and complements Eurotrace with a web-based, multi-user experience, built-in database and data lake, and scalable, containerized deployment options.
TDT’s core value is to take raw administrative trade data (customs declarations, registers, ministry records) and transform it into validated, aggregated statistics ready for publication workflows—using configurable pipelines and rules.
Positioning vs. Eurotrace: Eurotrace remains available (no near-term plans to discontinue), but no further improvements are planned; TDT is the forward-looking, cloud-first complement.
Core Functional Features
- Modern Upgrade of Eurotrace: Built from scratch with Eurotrace capabilities plus new enhancements.
- End-to-end compilation: Import raw files → validate and standardize → generate aggregates (e.g., IMTS) → export for distribution/publishing systems.
- Medallion Architecture: Organizes data into three layers—Bronze (raw), Silver (validated), Gold (aggregated) for quality control, structured processing, and lower learning curves.
- Modern data pipelines: ETL workflows for moving data from Bronze → Silver → Gold, including system and custom validations.
- Data validation & verification: Standard and custom checks are applied across the process; error handling and correction are part of the pipeline jobs.
- Error Management: Supports error rectification and batch reprocessing.
- Advanced Analytics: Users can run machine learning code via notebooks connected to TDT datasets.
- Built-in services:
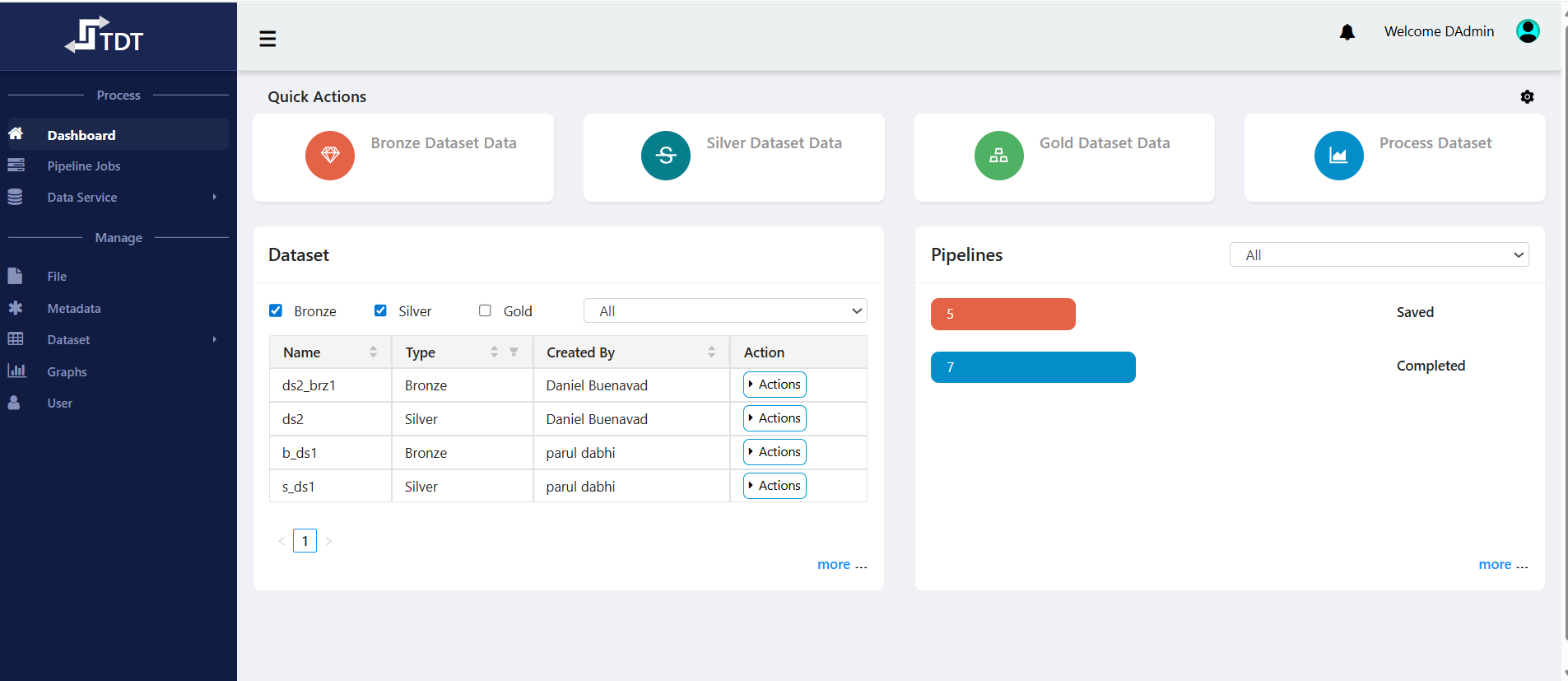
Dashboard: Quick access to datasets and last pipeline runs.
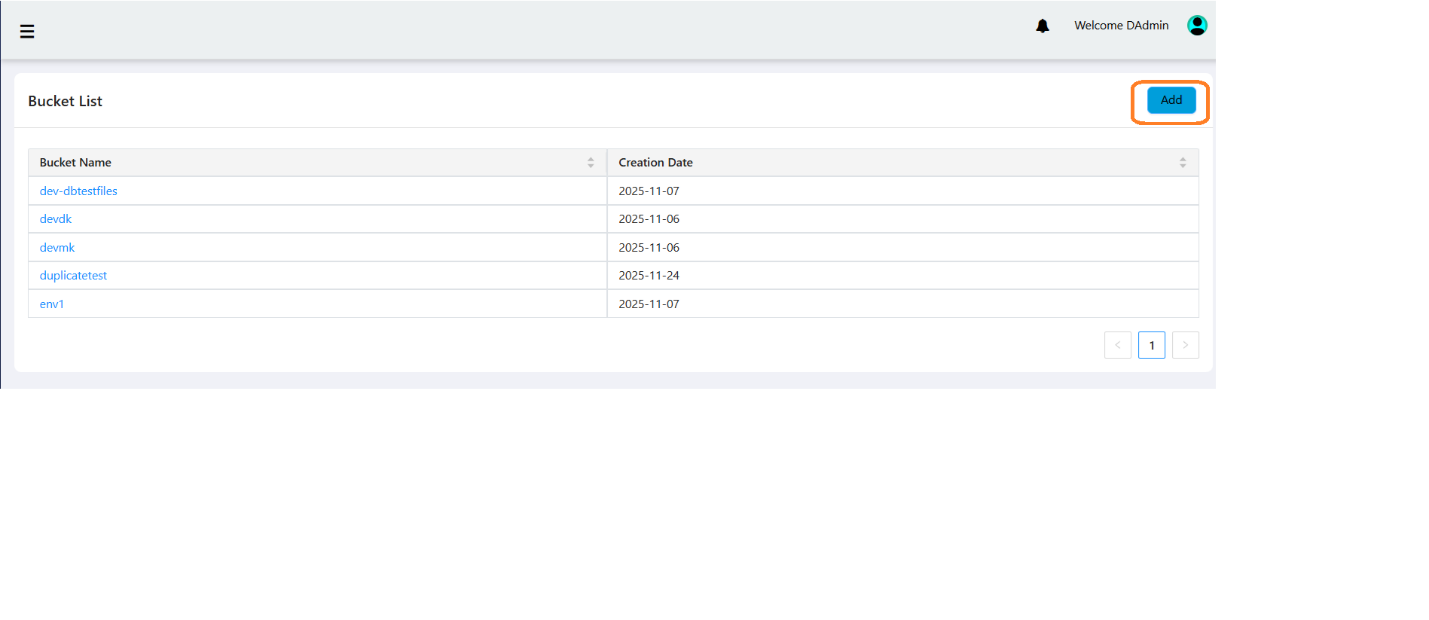
File Service (bucket-based) for secure storage and organization,
Metadata Service for schema & validation rules,
Dataset Service for domain structures,
Pipeline Jobs for ETL orchestration,
Data Service for tabular inspection/QA,
Charting for data visualization.
What TDT is not
- A PDF report generator with advanced publication layout,
- A full-blown visualization portal,
- A public data extraction site for general users.
These are intentionally out of scope; TDT focuses on compilation and upstream data quality.
Technical Features
- Microservices pattern: Separate services for files (minIO), data pipelines (Zeppelin), database (MariaDB), and web UI; open-source stack and no license requirements.
- Web-Based & Multi-User: Accessible through a browser, supports multiple users simultaneously.
- In-Built Database & Data Lake: No need for external databases or licenses; integrated storage for raw and processed data.
- Cloud-First Design: Runs in a secure, isolated cloud environment; can also be deployed on-premises or locally if needed.
- Open-Source Architecture: All components (file service, database, metadata) are open source; no licensing costs.
- Seamless Updates: System updates without full reinstallation.
- User access: Multi-user operations are emphasized for collaborative compilation environments.
Why TDT
TDT is a production-grade compilation tool with cloud/on-prem options that Eurotrace users can transition progressively; training and MVP testing are underway.
Deployment with microservices, open-source components, Kubernetes-based deployments, and a clear separation of services (UI, notebooks, storage).
Improving quality, timeliness, and scalability of IMTS, leading to better data availability in global trade databases (e.g., UN Comtrade) for better and timely policy decisions.
Functional Modules and Features
Dashboard
- Provides a quick overview of datasets (Bronze, Silver, Gold), pipelines, and shortcuts for frequent actions.
File Service
- Upload, organize, and manage files in user-defined buckets (directories).
- Supports adding/removing files, downloading, deleting, and overwriting files.
- Enables tagging files for dataset, metadata, or relationship purposes
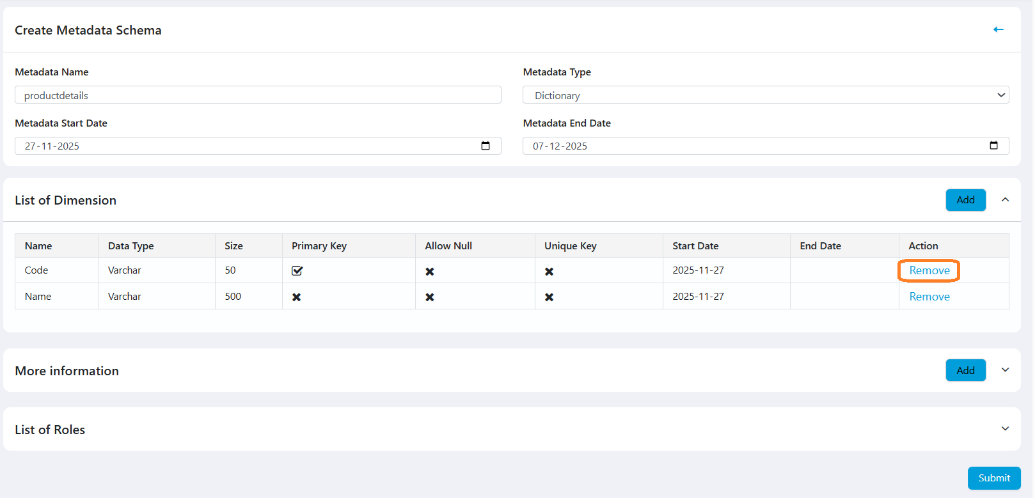
Metadata Service
- Create and manage metadata structures (dictionaries, relations).
- Define dimensions (columns), data types, primary keys, and access roles.
- Import/export metadata and view or clone metadata tables.
- Initialize metadata to lock structure and create corresponding database tables.
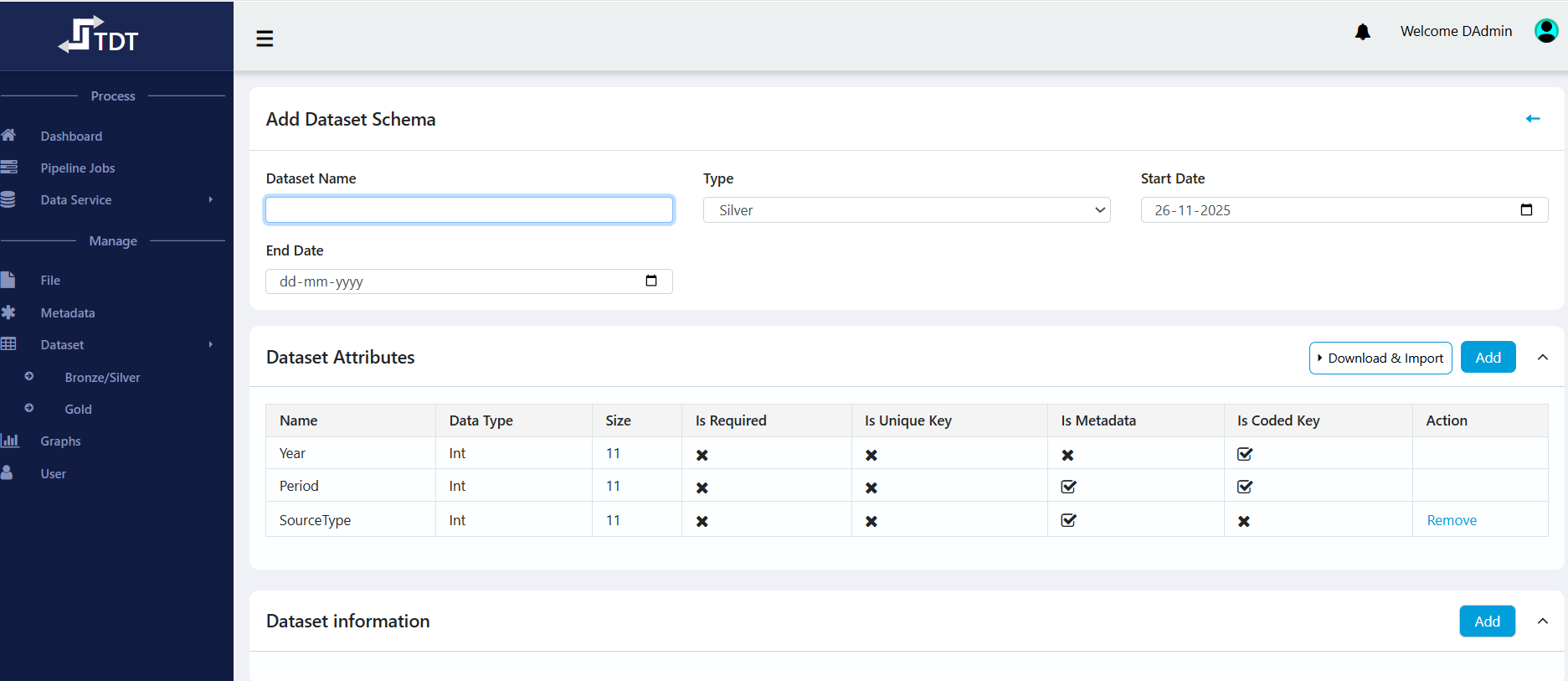
Dataset Management
- Create and manage three types of datasets:
- Bronze: Raw, unprocessed data (imported from files).
- Silver: Cleaned, validated data (result of ETL from Bronze).
- Gold: Aggregated, derived data (from Silver, for reporting).
- Define dataset structure, attributes, and link to metadata.
- Clone datasets, initialize to lock structure, and manage dataset versions.
Pipeline Jobs (ETL)
- Configure and run ETL (Extract, Transform, Load) pipelines for data processing.
- Use Apache Zeppelin notebooks for custom rule creation (SQL, validation, transformation).
- Map rules to datasets and execute in sequence.
- Monitor pipeline status and view job summaries.
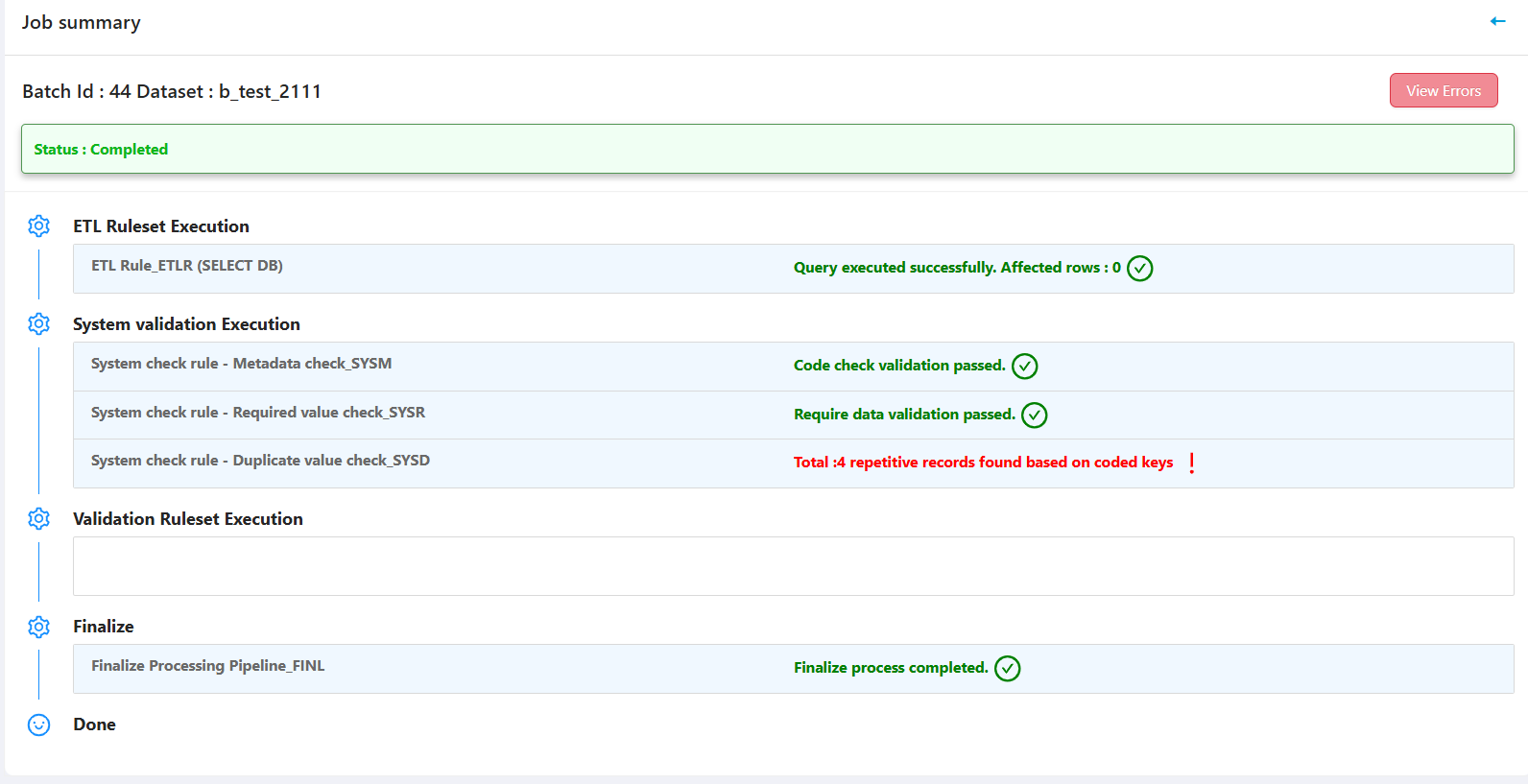
Error Management
- Identify, review, and correct errors in imported data (invalid codes, empty values, duplicates, custom checks).
- Edit records directly, resolve errors, and reprocess or re-run pipelines as needed.
- Corrections can be applied before finalizing data in Silver or Gold datasets.
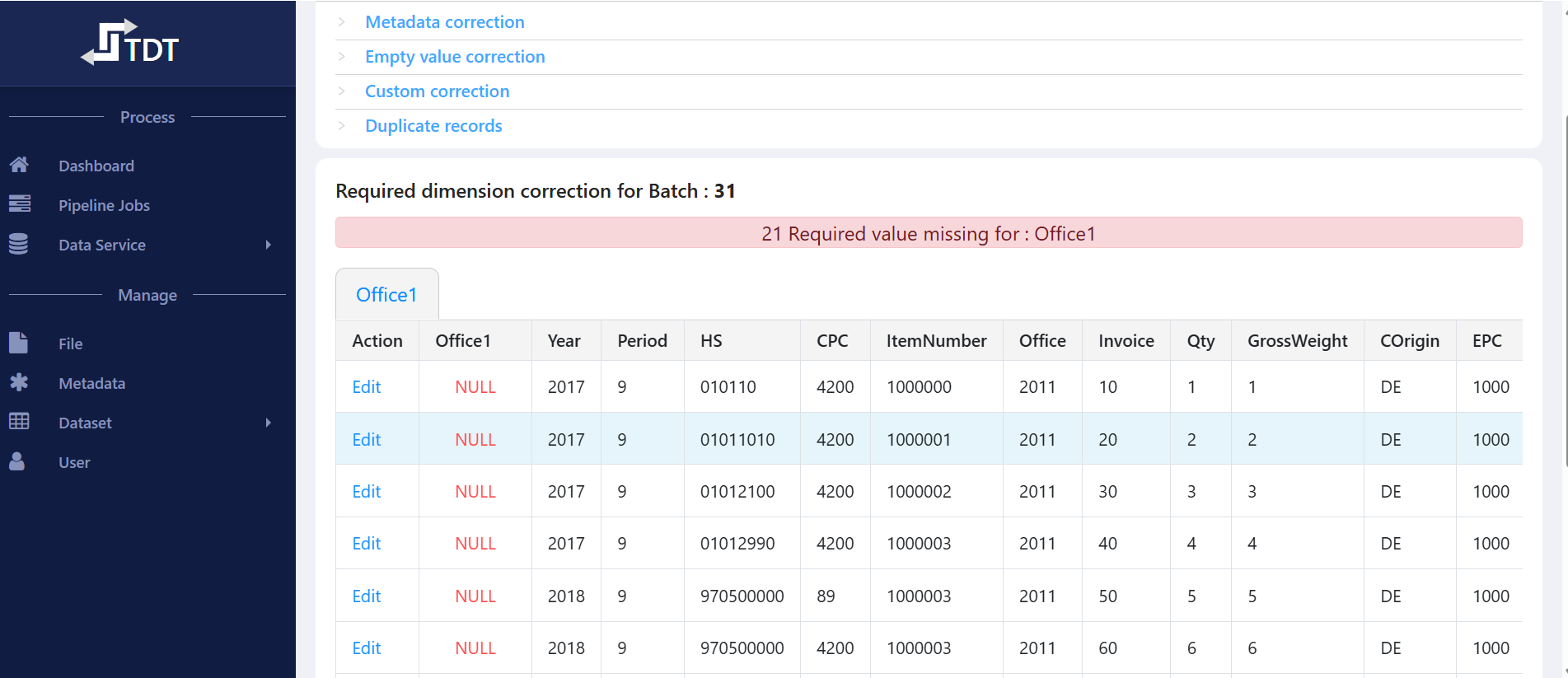
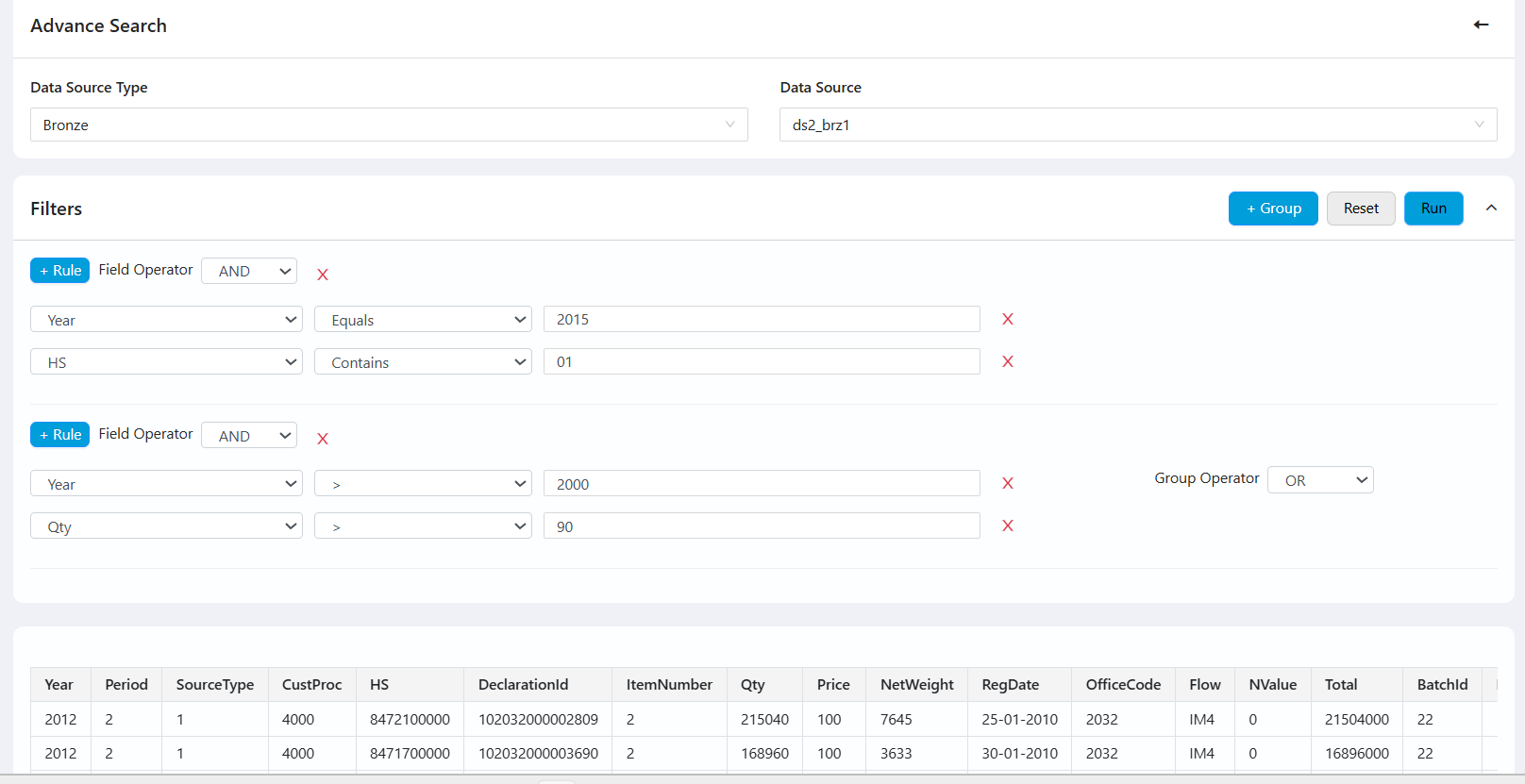
Data Service
- Visualize and search data in tabular format for all dataset types and metadata.
- Advanced search with complex filter logic (AND/OR groups, multiple conditions).
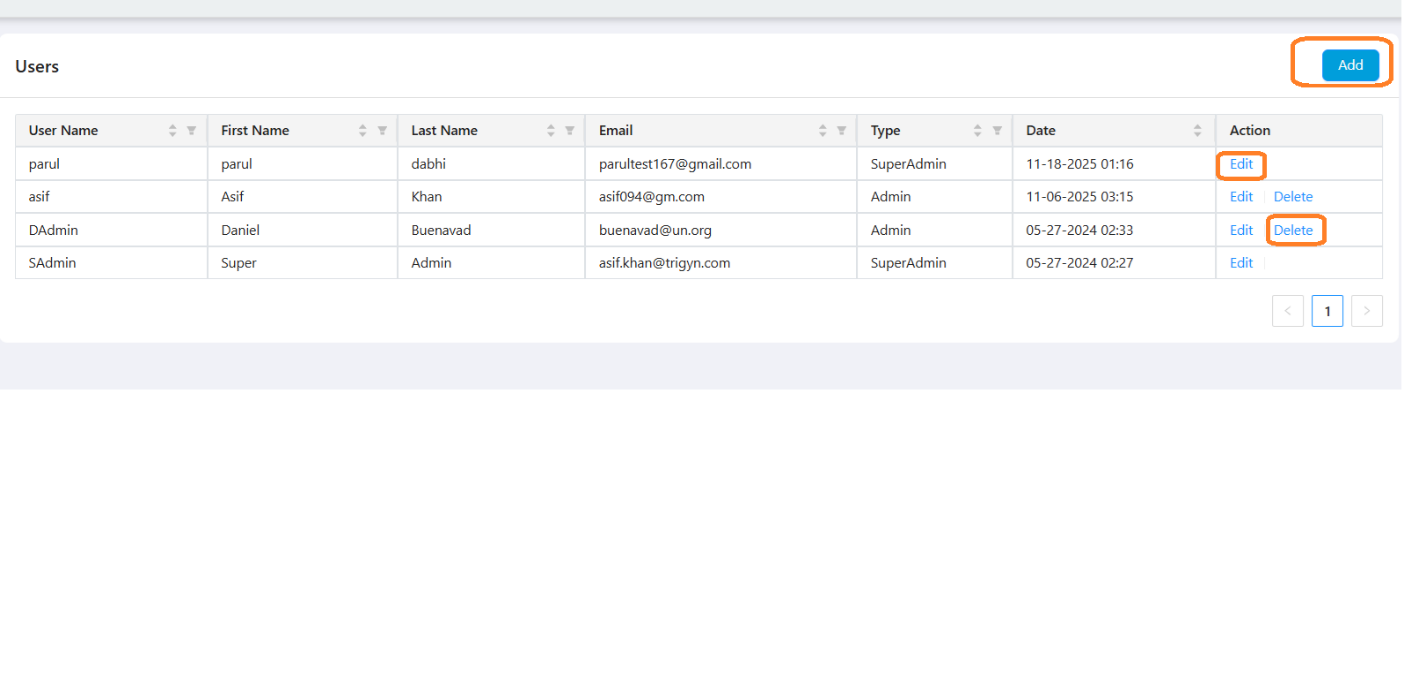
User Management
- Add, edit, or delete users.
- Assign roles and manage user access and credentials.
Charts & Visualization
- Create, edit, and manage data visualization charts (bar, pie, etc.).
- Configure chart properties, datasets, axes, filters, and aggregation functions.
- Manual and automated job processing for chart generation.
- Download chart images and view chart status.
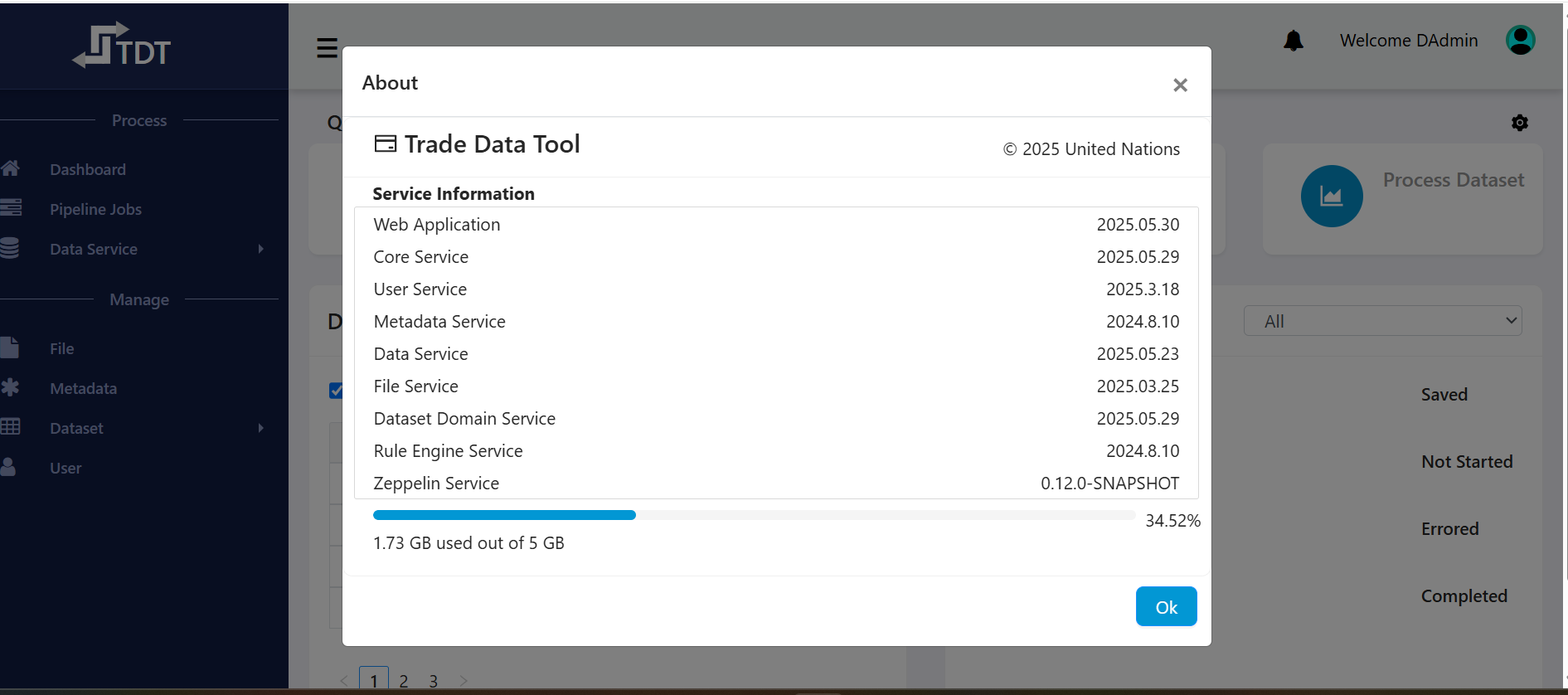
System Configuration & About
- Super Admins can configure system-wide parameters (e.g., file storage limits).
- "About" dialog shows application version, deployed services, and storage usage
Data Access through API
- Gold datasets can be reached via a REST API to enhance compatibility with various tools like PowerBI or Excel.
- The primary rationale is that TDT is not designed as a dissemination platform, so it needs to connect with other established tools.
- (future) There is potential to extend this functionality to enable “common” statistical data dissemination tools to access TDT through an API.
TDT development and deployment activities
Activities in 2026
Eurostat and UNSD continued to develop and test the TDT with the aim of Version 1 in 2026. Version 1 will also be made available as open source.
Further, the TDT regional training will be organized in April 2026, hosted by the African Union Commission.
Activities in 2025
The bugs identified in the TDT assessment exercises in 2024 were being fixed in 2025 to ensure that the application functions optimally, with minimal disruptions or issues. The identified bugs include performance issues, data display errors, and other technical issues that may hinder usability. Another major update was the applicability of using on-premises to run TDT.
Further, in early 2025, it was planned to make minor updates to the user interface (UI) and microservices, as well as to implement a new Editor module that will enable users to update their data freely. It is also foreseen to look for a basic visualization tool that could be improved in 2026.
In December 2025, the training on the use of TDT was organized in Guyana, attended by the trade statistician and IT experts from the Guyana Bureau of Statistics and CARICOM Secretariat.
Activities in 2024
In early 2024, the team undertook a mission to implement a Proof of Concept in Eswatini, using real data and validation rules. At this point, the working prototype, various user guides for installation and configuration, and some training materials were prepared. One of the mission outcomes was the need to have TDT on-premises in addition to TDT local and TDT cloud, considering the needs of countries. For the rest of 2024, the technical team continued to improve the TDT in various aspects, including on-premises deployment and user interface (UI). Further, TDT was presented in several trade technical working groups organized by regional organizations.
Activities in 2022 and 2023
In 2022, the initial plan was to stabilize and expand the modules while conducting a pilot project for experimentation and testing. However, due to changes in technology selection, the focus shifted to modifying and stabilizing the core modules, particularly to develop the minimum viable product (MVP) for testing (details on status are provided below). The involvement of two experts with extensive experience in the implementation of Eurotrace allowed the team to address the requirements identified in the TDT prototype developed in 2021.
In March 2023, the MVP and a draft of the user manual were released for the next stage of implementation, which included awareness activities and pilot implementation throughout the remainder of 2023. So far, TDT has been presented at the following events:
- East African Community (EAC) in-person workshop in March 2023
- African Union Commission (AUC) in-person Specialized Technical Group in April 2023
- Southern African Customs Union (SACU) in-person workshop in May 2023
- Association of Southeast Asian Nations (ASEAN) virtual Expert Group meeting in September 2023
Activities in 2020-2021
In 2020, the United Nations Statistics Division (UNSD) conducted a global assessment survey to evaluate existing trade compilation tools, including Eurotrace and PC Trade. This survey focused on identifying functional requirements and potential improvements. Following the survey, a virtual focus group meeting was held at the beginning of 2021, featuring participants from countries that utilize Eurotrace and PC Trade. Both initiatives resulted in detailed specification documents that guided the development of new tools.
In 2021, most activities centered on the development of trade data tools, which were managed by IT contractors under the supervision of UNSD and Eurostat project managers. The development process focused on the following modules:
- Architecture and infrastructure design
- User experience/interface design and development
- Development of core modules, including metadata, data management, file handling, a rule engine, data pipeline, error engine, and gold data creation
Additionally, in 2021, preliminary user guidelines and manuals were drafted, and several tests were conducted.
Eurotace vs. TDT
In terms of features, Eurotrace and TDT are very similar – both aim to assist compilers in compiling trade data; and TDT was built from scratch based on Eurotrace. However, there are some differences in terminologies and ways to define the structure and rules. Furthermore, to assist the understanding of TDT deployment, the tables below shows the non-functional and functional features between Eurotrace and TDT
Table 1. Comparison of
| Eurotrace | TDT | |
|---|---|---|
| Ability to directly interact with datasets in the database (access controlled) | No (Access version), Yes (SQL Server version) | Yes |
| Ability to scale horizontally to process multiple datasets at a time (multiple servers serving in parallel) | No | Yes |
| Ability to deploy on multiple platforms (cloud, client-server and local deployment) | No (only local deployment with remote database) | Yes |
| Ability to add new components on the go (without deploying) | No | Yes |
| Ability to scale services independently (for example, Scale only pipeline services as it does most of the heavy lifting) | No | Yes |
| Is technology/programming language agnostic? | No | Yes (designed as a set of independent microservices) |
| Licenses required? | Yes/No (needed if SQL server or Oracle databases are used) | No (all the tools used are open source, including the database Mariadb) |
| Data storage (to persist the uploaded files and other reference files as required) | No | Yes (through file service, which uses Minio behind the scenes) |
| Support for multiple data analytical languages such as SQL/Python/R | Only SQL (templated versions) | Yes |
| Possibility to integrate with user's own data source for cross-analysis | No | Yes (through Zeppelin notebooks with connectors) |
Table 2. Comparison of
| Eurotrace | TDT | |
|---|---|---|
| Core Purpose | Compilation of IMTS (International Merchandise Trade Statistics) using modular desktop tools. | Modern, modular platform for IMTS with web-based, multi-user experience and cloud readiness. It can also be extended to different domains. |
| Data Processing Workflow | Import → Validate → Aggregate → Export (mostly manual steps). | End-to-end automated pipeline: Import raw files → Validate & standardize → Aggregate → Export. |
| Data Architecture | Single-layer database (Eurotrace DBMS). | Medallion Architecture: Bronze (raw), Silver (validated), Gold (aggregated) for structured quality control. |
| Validation & Error Handling | Basic validation during data entry; limited error correction. | Advanced validation (system + custom rules), error rectification, and batch reprocessing built-in. |
| Metadata Management | Dictionary and classification plan manually maintained. | Metadata Service for schema, validation rules, and relationships; dynamic updates possible. |
| Dataset Management | Manual dataset creation and import; limited automation. | Dataset Service for schema, constraints based on metadata, and automated ETL pipelines. |
| File Handling | Manual file upload and mapping; text file interpreter integrated. | File Service with bucket-based secure storage; supports mapping to datasets. |
| Rule Engine | SQL-based user-defined queries for validation. | Zeppelin notebooks for complex rules, analytics, and machine learning integration with support for multiple data analytical languages such as SQL/Python/R |
| Analytics & Reporting | Basic tabular outputs via COMEXT standalone. | Dashboards for pipeline runs and dataset status. Advanced analytics with ML support with Zeppelin. |
| Deployment & Access | Local deployment with remote DB; single-user or limited multi-user. | Multi-platform (cloud, client-server, local); scalable, containerized, multi-user web interface. |
| Extensibility | Static modules; upgrades require full redeployment. | Modular microservices; new components can be added without downtime. |
| Integration | Limited to Eurotrace ecosystem; manual linking to external sources. | Integrates with external data sources for cross-analysis via connectors and notebooks. |
TDT Data Architectures
Bronze, silver, and gold datasets:
TDT (Trade data tools) manages data at different levels, which are referred to as "Bronze," "Silver," and "Gold." These terms are derived from the data lake concept, primarily used by the Delta Lake project of Apache Spark. The Bronze level represents raw data in its original form, and any data fed into the system will initially land in the Bronze zone. The Silver level represents curated and disaggregated data resulting from applying necessary rules defined in the system to the Bronze data. The Silver level also serves as a single source of truth. The Gold level represents more curated and aggregated data and can be compared to data cubes in data warehousing. Users can create as many Gold datasets as they need from Silver data and have as many Bronze (source) datasets as required. However, only one Silver dataset is possible. The diagram below illustrates these levels.

Apache Zeppelin
It is an open-source web-based notebook that provides an interactive environment for data ingestion, exploration, visualization, and collaboration. A Zeppelin notebook is an interface that allows users to execute code and view the results of that code, including visualizations and textual output. Zeppelin notebooks consist of paragraphs similar to cells in a Jupyter notebook. Zeppelin notebooks are designed for admins and SQL experts who access the database directly from this tool, allowing them to test their rules and analyze their data in the TDT.
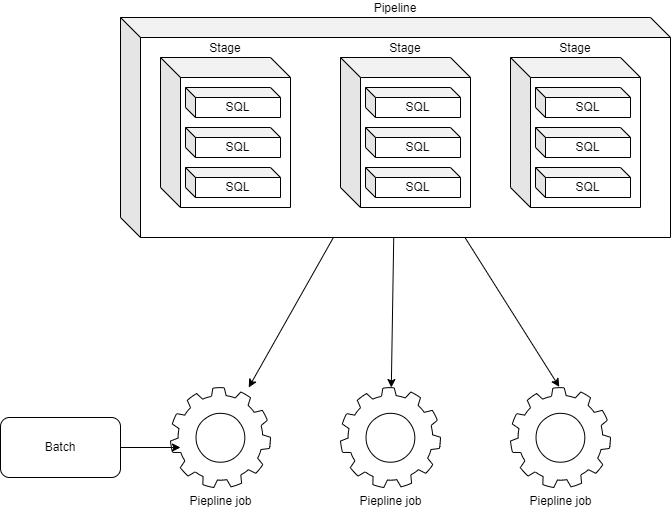
Pipelines
TDT manages rules in the form of pipelines. A pipeline contains many stages, each containing a ruleset (or Zeppelin notebook). Ruleset contains a set of SQL queries that are applied to the bronze data to produce silver data or applied to silver data to produce gold data. These rules are defined inside the Zeppelin notebook. Pipelines consist of multiple stages, each consisting of one Zeppelin notebook. Each notebook contains multiple rulesets, which represent individual SQL queries.
Contact
Please reach out to comtrade@un.org if you would like to learn more or be part of the pilot implementation.